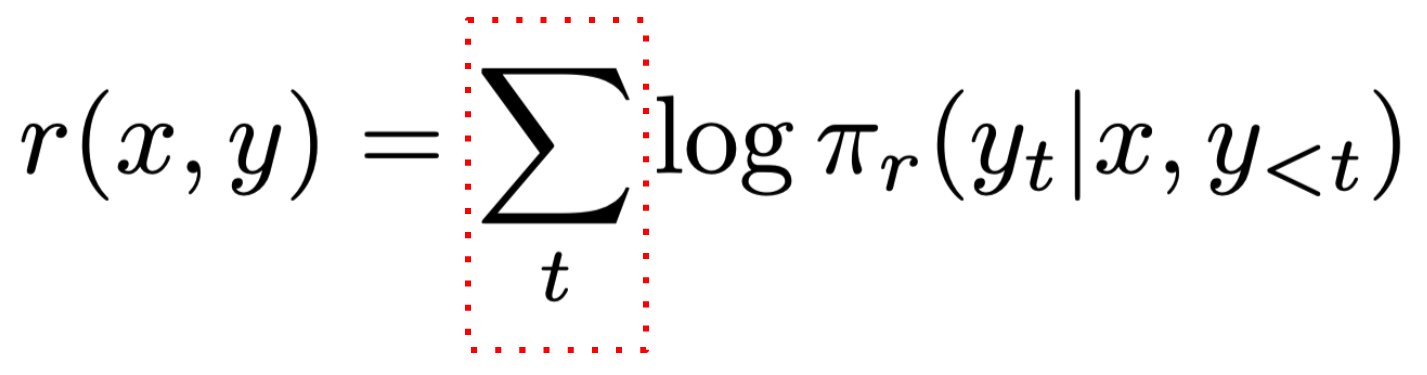❌ Traditional reward models = Slow 🚶
🔹They score entire responses post-generation 📜
🔹LLMs must generate fully before evaluation ⏳
✅ GenARM = Fast 🏎️
🔹 Predicts next-token rewards on the fly ⚡
🔹 Guides LLMs token by token—drastically improving efficiency! 💡
What’s an Autoregressive Reward Model?
Unlike conventional trajectory-level reward models, GenARM parametrizes rewards at the token level:
🔹 Rewards decompose naturally as log probabilities 🔄
🔹 Each token selection is guided dynamically 🎯